
Redis集群架构介绍
redis-cluster是近年来redis架构不断改进中的相对较好的redis高可用方案。本文涉及到近年来redis多实例架构的演变过程,包括普通主从架构(Master、slave可进行写读分离)、哨兵模式下的主从架构、redis-cluster高可用架构(redis官方默认cluster下不进行读写分离)的简介。同时还介绍使用Java的两大redis客户端:Jedis与Lettuce用于读写redis-cluster的数据的一般方法。
近年来redis多实例用架构的演变过程
redis是基于内存的高性能key-value数据库,若要让redis的数据更稳定安全,需要引入多实例以及相关的高可用架构。而近年来redis的高可用架构亦不断改进,先后出现了本地持久化、主从备份、哨兵模式、redis-cluster群集高可用架构等等方案。
1、redis普通主从模式
通过持久化功能,Redis保证了即使在服务器重启的情况下也不会损失(或少量损失)数据,因为持久化会把内存中数据保存到硬盘上,重启会从硬盘上加载数据。但是由于数据是存储在一台服务器上的,如果这台服务器出现硬盘故障等问题,也会导致数据丢失。为了避免单点故障,通常的做法是将数据库复制多个副本以部署在不同的服务器上,这样即使有一台服务器出现故障,其他服务器依然可以继续提供服务。为此, Redis 提供了复制(replication)功能,可以实现当一台数据库中的数据更新后,自动将更新的数据同步到其他数据库上。
在复制的概念中,数据库分为两类,一类是主数据库(master),另一类是从数据库(slave)。主数据库可以进行读写操作,当写操作导致数据变化时会自动将数据同步给从数据库。而从数据库一般是只读的,并接受主数据库同步过来的数据。一个主数据库可以拥有多个从数据库,而一个从数据库只能拥有一个主数据库。
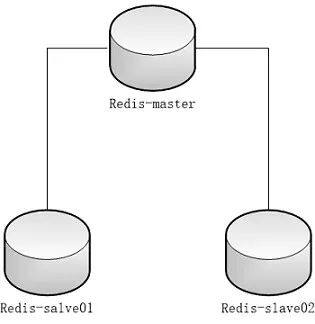
主从模式的配置,一般只需要再作为slave的redis节点的conf文件上加入“slaveof masterip masterport”, 或者作为slave的redis节点启动时使用如下参考命令:
redis-server --port 6380 --slaveof masterIp masterPort
redis的普通主从模式,能较好地避免单独故障问题,以及提出了读写分离,降低了Master节点的压力。互联网上大多数的对redis读写分离的教程,都是基于这一模式或架构下进行的。但实际上这一架构并非是目前最好的redis高可用架构。
2、redis哨兵模式高可用架构
当主数据库遇到异常中断服务后,开发者可以通过手动的方式选择一个从数据库来升格为主数据库,以使得系统能够继续提供服务。然而整个过程相对麻烦且需要人工介入,难以实现自动化。为此,Redis 2.8开始提供了哨兵工具来实现自动化的系统监控和故障恢复功能。哨兵的作用就是监控redis主、从数据库是否正常运行,主出现故障自动将从数据库转换为主数据库。
顾名思义,哨兵的作用就是监控Redis系统的运行状况。它的功能包括以下两个。
(1)监控主数据库和从数据库是否正常运行。
(2)主数据库出现故障时自动将从数据库转换为主数据库。
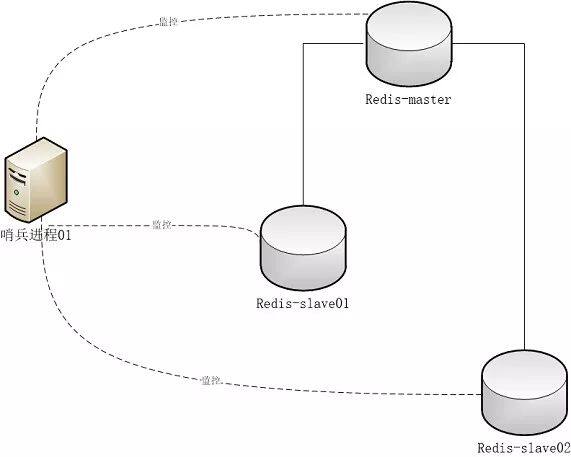
可以用info replication查看主从情况 例子: 1主2从 1哨兵,可以用命令起也可以用配置文件里 可以使用双哨兵,更安全,参考命令如下:
redis-server --port 6379 redis-server --port 6380 --slaveof 192.168.0.167 6379 redis-server --port 6381 --slaveof 192.168.0.167 6379 redis-sentinel sentinel.conf
其中,哨兵配置文件sentinel.conf参考如下:
sentinel monitor mymaster 192.168.0.167 6379 1
其中mymaster表示要监控的主数据库的名字。配置哨兵监控一个系统时,只需要配置其监控主数据库即可,哨兵会自动发现所有复制该主数据库的从数据库。
Master与slave的切换过程:
(1)slave leader升级为master
(2)其他slave修改为新master的slave
(3)客户端修改连接
(4)老的master如果重启成功,变为新master的slave
3、redis-cluster群集高可用架构
即使使用哨兵,redis每个实例也是全量存储,每个redis存储的内容都是完整的数据,浪费内存且有木桶效应。为了最大化利用内存,可以采用cluster群集,就是分布式存储。即每台redis存储不同的内容。
采用redis-cluster架构正是满足这种分布式存储要求的集群的一种体现。redis-cluster架构中,被设计成共有16384个hash slot。每个master分得一部分slot,其算法为:hash_slot = crc16(key) mod 16384 ,这就找到对应slot。采用hash slot的算法,实际上是解决了redis-cluster架构下,有多个master节点的时候,数据如何分布到这些节点上去。key是可用key,如果有{}则取{}内的作为可用key,否则整个可以是可用key。群集至少需要3主3从,且每个实例使用不同的配置文件。
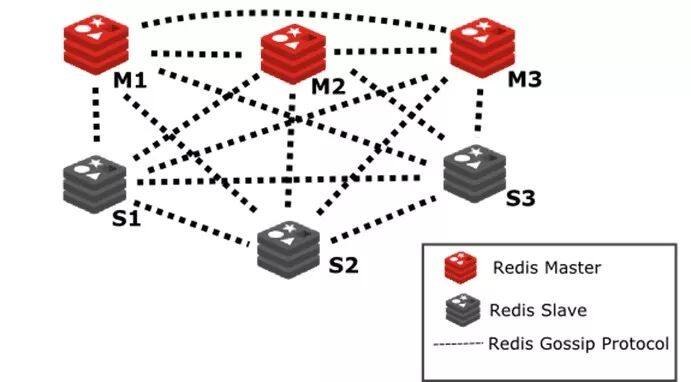
在redis-cluster架构中,redis-master节点一般用于接收读写,而redis-slave节点则一般只用于备份,其与对应的master拥有相同的slot集合,若某个redis-master意外失效,则再将其对应的slave进行升级为临时redis-master。
在redis的官方文档中,对redis-cluster架构上,有这样的说明:在cluster架构下,默认的,一般redis-master用于接收读写,而redis-slave则用于备份,当有请求是在向slave发起时,会直接重定向到对应key所在的master来处理。但如果不介意读取的是redis-cluster中有可能过期的数据并且对写请求不感兴趣时,则亦可通过readonly命令,将slave设置成可读,然后通过slave获取相关的key,达到读写分离。具体可以参阅redis官方文档(https://redis.io/commands/readonly)等相关内容。
例如,我们假设已经建立了一个三主三从的redis-cluster架构,其中A、B、C节点都是redis-master节点,A1、B1、C1节点都是对应的redis-slave节点。在我们只有master节点A,B,C的情况下,对应redis-cluster如果节点B失败,则群集无法继续,因为我们没有办法再在节点B的所具有的约三分之一的hash slot集合范围内提供相对应的slot。然而,如果我们为每个主服务器节点添加一个从服务器节点,以便最终集群由作为主服务器节点的A,B,C以及作为从服务器节点的A1,B1,C1组成,那么如果节点B发生故障,系统能够继续运行。节点B1复制B,并且B失效时,则redis-cluster将促使B的从节点B1作为新的主服务器节点并且将继续正确地操作。但请注意,如果节点B和B1在同一时间发生故障,则Redis群集无法继续运行。
Java中对redis-cluster数据的一般读取方法简介
使用Jedis读写redis-cluster的数据
由于Jedis类一般只能对一台redis-master进行数据操作,所以面对redis-cluster多台master与slave的群集,Jedis类就不能满足了。这个时候我们需要引用另外一个操作类:JedisCluster类。
例如我们有6台机器组成的redis-cluster:
172.20.52.85:7000、 172.20.52.85:7001、172.20.52.85:7002、172.20.52.85:7003、172.20.52.85:7004、172.20.52.85:7005
其中master机器对应端口:7000、7004、7005
slave对应端口:7001、7002、7003
使用JedisCluster对redis-cluster进行数据操作的参考代码如下:
// 添加nodes服务节点到Set集合
Set<HostAndPort> hostAndPortsSet = new HashSet<HostAndPort>();
// 添加节点
hostAndPortsSet.add(new HostAndPort("172.20.52.85", 7000));
hostAndPortsSet.add(new HostAndPort("172.20.52.85", 7001));
hostAndPortsSet.add(new HostAndPort("172.20.52.85", 7002));
hostAndPortsSet.add(new HostAndPort("172.20.52.85", 7003));
hostAndPortsSet.add(new HostAndPort("172.20.52.85", 7004));
hostAndPortsSet.add(new HostAndPort("172.20.52.85", 7005));
// Jedis连接池配置
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(100);
jedisPoolConfig.setMaxTotal(500);
jedisPoolConfig.setMinIdle(0);
jedisPoolConfig.setMaxWaitMillis(2000); // 设置2秒
jedisPoolConfig.setTestOnBorrow(true);
JedisCluster jedisCluster = new JedisCluster(hostAndPortsSet ,jedisPoolConfig);
String result = jedisCluster.get("event:10");
System.out.println(result);
第一节中我们已经介绍了redis-cluster架构下master提供读写功能,而slave一般只作为对应master机器的数据备份不提供读写。如果我们只在hostAndPortsSet中只配置slave,而不配置master,实际上还是可以读到数据,但其内部操作实际是通过slave重定向到相关的master主机上,然后再将结果获取和输出。
上面是普通项目使用JedisCluster的简单过程,若在spring boot项目中,可以定义JedisConfig类,使用@Configuration、@Value、@Bean等一些列注解完成JedisCluster的配置,然后再注入该JedisCluster到相关service逻辑中引用,这里介绍略。
使用Lettuce读写redis-cluster数据
Lettuce 和 Jedis 的定位都是Redis的client。Jedis在实现上是直接连接的redis server,如果在多线程环境下是非线程安全的,这个时候只有使用连接池,为每个Jedis实例增加物理连接,每个线程都去拿自己的 Jedis 实例,当连接数量增多时,物理连接成本就较高了。
Lettuce的连接是基于Netty的,连接实例(StatefulRedisConnection)可以在多个线程间并发访问,应为StatefulRedisConnection是线程安全的,所以一个连接实例(StatefulRedisConnection)就可以满足多线程环境下的并发访问,当然这个也是可伸缩的设计,一个连接实例不够的情况也可以按需增加连接实例。
其中spring boot 2.X版本中,依赖的spring-session-data-redis已经默认替换成Lettuce了。
同样,例如我们有6台机器组成的redis-cluster:
172.20.52.85:7000、 172.20.52.85:7001、172.20.52.85:7002、172.20.52.85:7003、172.20.52.85:7004、172.20.52.85:7005
其中master机器对应端口:7000、7004、7005
slave对应端口:7001、7002、7003
在spring boot 2.X版本中使用Lettuce操作redis-cluster数据的方法参考如下:
(1)pom文件参考如下:
parent中指出spring boot的版本,要求2.X以上:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.4.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
依赖中需要加入spring-boot-starter-data-redis,参考如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
(2)springboot的配置文件要包含如下内容:
spring.redis.database=0
spring.redis.lettuce.pool.max-idle=10
spring.redis.lettuce.pool.max-wait=500
spring.redis.cluster.timeout=1000
spring.redis.cluster.max-redirects=3
spring.redis.cluster.nodes=172.20.52.85:7000,172.20.52.85:7001,172.20.52.85:7002,172.20.52.85:7003,172.20.52.85:7004,172.20.52.85:7005
(3)新建RedisConfiguration类,参考代码如下:
@Configuration
public class RedisConfiguration {
[@Resource](https://my.oschina.net/u/929718)
private LettuceConnectionFactory myLettuceConnectionFactory;
@Bean
public RedisTemplate<String, Serializable> redisTemplate() {
RedisTemplate<String, Serializable> template = new RedisTemplate<>();
template.setKeySerializer(new StringRedisSerializer());
//template.setValueSerializer(new GenericJackson2JsonRedisSerializer());
template.setValueSerializer(new StringRedisSerializer());
template.setConnectionFactory(myLettuceConnectionFactory);
return template;
}
}
(4)新建RedisFactoryConfig类,参考代码如下:
@Configuration
public class RedisFactoryConfig {
@Autowired
private Environment environment;
@Bean
public RedisConnectionFactory myLettuceConnectionFactory() {
Map<String, Object> source = new HashMap<String, Object>();
source.put("spring.redis.cluster.nodes", environment.getProperty("spring.redis.cluster.nodes"));
source.put("spring.redis.cluster.timeout", environment.getProperty("spring.redis.cluster.timeout"));
source.put("spring.redis.cluster.max-redirects", environment.getProperty("spring.redis.cluster.max-redirects"));
RedisClusterConfiguration redisClusterConfiguration;
redisClusterConfiguration = new RedisClusterConfiguration(new MapPropertySource("RedisClusterConfiguration", source));
return new LettuceConnectionFactory(redisClusterConfiguration);
}
}
(5)在业务类service中注入Lettuce相关的RedisTemplate,进行相关操作。以下是我化简到了springbootstarter中进行,参考代码如下:
@SpringBootApplication
public class NewRedisClientApplication {
public static void main(String[] args) {
ApplicationContext context = SpringApplication.run(NewRedisClientApplication.class, args);
RedisTemplate redisTemplate = (RedisTemplate)context.getBean("redisTemplate");
String rtnValue = (String)redisTemplate.opsForValue().get("event:10");
System.out.println(rtnValue);
}
}
以上的介绍,是采用Jedis以及Lettuce对redis-cluster数据的简单读取。Jedis也好,Lettuce也好,其对于redis-cluster架构下的数据的读取,都是默认是按照redis官方对redis-cluster的设计,自动进行重定向到master节点中进行的,哪怕是我们在配置中列出了所有的master节点和slave节点。
查阅了Jedis以及Lettuce的github上的源码,默认不支持redis-cluster下的读写分离,可以看出Jedis若要支持redis-cluster架构下的读写分离,需要自己改写和构建多一些包装类,定义好Master和slave节点的逻辑;而Lettuce的源码中,实际上预留了方法(setReadForm(ReadFrom.SLAVE))进行redis-cluster架构下的读写分离,相对来说修改会简单一些。
总结
总体上来说,redis-cluster高可用架构方案是目前最好的redis架构方案,redis的官方对redis-cluster架构是建议redis-master用于接收读写,而redis-slave则用于备份(备用),默认不建议读写分离。但如果不介意读取的是redis-cluster中有可能过期的数据并且对写请求不感兴趣时,则亦可通过readonly命令,将slave设置成可读,然后通过slave获取相关的key,达到读写分离。
Jedis、Lettuce都可以进行redis-cluster的读写操作,而且默认只针对Master进行读写,若要对redis-cluster架构下进行读写分离,则Jedis需要进行源码的较大改动,而Lettuce开放了setReadFrom()方法,可以进行二次封装成读写分离的客户端,相对简单,而且Lettuce比Jedis更安全。redis-cluster架构下可以直接通过水平扩展master来达到性能的提升。