
1. 前言
LVS集群中实现的三种IP负载均衡技术,它们主要解决系统的可伸缩性和透明性问题,如何通过负载调度器将请求高 效地分发到不同的服务器执行,使得由多台独立计算机组成的集群系统成为一台虚拟服务器;客户端应用程序与集群系统交互时,就像与一台高性能的服务器交互一 样。
本文将主要讲述在负载调度器上的负载调度策略和算法,如何将请求流调度到各台服务器,使得各台服务器尽可能地保持负载均衡。文章主要由两个部分组 成。第一部分描述IP负载均衡软件IPVS在内核中所实现的各种连接调度算法;第二部分给出一个动态反馈负载均衡算法(Dynamic-feedback load balancing),它结合内核中的加权连接调度算法,根据动态反馈回来的负载信息来调整服务器的权值,来进一步避免服务器间的负载不平衡。
在下面描述中,我们称客户的socket和服务器的socket之间的数据通讯为连接,无论它们是使用TCP还是UDP协议。对于UDP数据报文的 调度,IPVS调度器也会为之建立调度记录并设置超时值(如5分钟);在设定的时间内,来自同一地址(IP地址和端口)的UDP数据包会被调度到同一台服 务器。
2. 内核中的连接调度算法
IPVS在内核中的负载均衡调度是以连接为粒度的。在HTTP协议(非持久)中,每个对象从WEB服务器上获取都需要建立一个TCP连接,同一用户 的不同请求会被调度到不同的服务器上,所以这种细粒度的调度在一定程度上可以避免单个用户访问的突发性引起服务器间的负载不平衡。
在内核中的连接调度算法上,IPVS已实现了以下八种调度算法:
- 轮叫调度(Round-Robin Scheduling)
- 加权轮叫调度(Weighted Round-Robin Scheduling)
- 最小连接调度(Least-Connection Scheduling)
- 加权最小连接调度(Weighted Least-Connection Scheduling)
- 基于局部性的最少链接(Locality-Based Least Connections Scheduling)
- 带复制的基于局部性最少链接(Locality-Based Least Connections with Replication Scheduling)
- 目标地址散列调度(Destination Hashing Scheduling)
- 源地址散列调度(Source Hashing Scheduling)
下面,我们先介绍这八种连接调度算法的工作原理和算法流程,会在以后的文章中描述怎么用它们。
2.1. 轮叫调度
轮叫调度(Round Robin Scheduling)算法就是以轮叫的方式依次将请求调度不同的服务器,即每次调度执行i = (i + 1) mod n,并选出第i台服务器。算法的优点是其简洁性,它无需记录当前所有连接的状态,所以它是一种无状态调度。
在系统实现时,我们引入了一个额外条件,当服务器的权值为零时,表示该服务器不可用而不被调度。这样做的目的是将服务器切出服务(如屏蔽服务器故障和系统维护),同时与其他加权算法保持一致。所以,算法要作相应的改动,它的算法流程如下:
轮叫调度算法流程
|
轮叫调度算法假设所有服务器处理性能均相同,不管服务器的当前连接数和响应速度。该算法相对简单,不适用于服务器组中处理性能不一的情况,而且当请求服务时间变化比较大时,轮叫调度算法容易导致服务器间的负载不平衡。
虽然Round-Robin DNS方法也是以轮叫调度的方式将一个域名解析到多个IP地址,但轮叫DNS方法的调度粒度是基于每个域名服务器的,域名服务器对域名解析的缓存会妨碍轮 叫解析域名生效,这会导致服务器间负载的严重不平衡。这里,IPVS轮叫调度算法的粒度是基于每个连接的,同一用户的不同连接都会被调度到不同的服务器 上,所以这种细粒度的轮叫调度要比DNS的轮叫调度优越很多。
2.2. 加权轮叫调度
加权轮叫调度(Weighted Round-Robin Scheduling)算法可以解决服务器间性能不一的情况,它用相应的权值表示服务器的处理性能,服务器的缺省权值为1。假设服务器A的权值为1,B的 权值为2,则表示服务器B的处理性能是A的两倍。加权轮叫调度算法是按权值的高低和轮叫方式分配请求到各服务器。权值高的服务器先收到的连接,权值高的服 务器比权值低的服务器处理更多的连接,相同权值的服务器处理相同数目的连接数。加权轮叫调度算法流程如下:
加权轮叫调度算法流程
|
例如,有三个服务器A、B和C分别有权值4、3和2,则在一个调度周期内(mod sum(W(Si)))调度序列为AABABCABC。加权轮叫调度算法还是比较简单和高效。当请求的服务时间变化很大,单独的加权轮叫调度算法依然会导致服务器间的负载不平衡。
从上面的算法流程中,我们可以看出当服务器的权值为零时,该服务器不被被调度;当所有服务器的权值为零,即对于任意i有W(Si)=0,则没有任何 服务器可用,算法返回NULL,所有的新连接都会被丢掉。加权轮叫调度也无需记录当前所有连接的状态,所以它也是一种无状态调度。
2.3. 最小连接调度
最小连接调度(Least-Connection Scheduling)算法是把新的连接请求分配到当前连接数最小的服务器。最小连接调度是一种动态调度算法,它通过服务器当前所活跃的连接数来估计服务 器的负载情况。调度器需要记录各个服务器已建立连接的数目,当一个请求被调度到某台服务器,其连接数加1;当连接中止或超时,其连接数减一。
在系统实现时,我们也引入当服务器的权值为零时,表示该服务器不可用而不被调度,它的算法流程如下:
最小连接调度算法流程
|
当各个服务器有相同的处理性能时,最小连接调度算法能把负载变化大的请求分布平滑到各个服务器上,所有处理时间比较长的请求不可能被发送到同一台服 务器上。但是,当各个服务器的处理能力不同时,该算法并不理想,因为TCP连接处理请求后会进入TIME_WAIT状态,TCP的TIME_WAIT一般 为2分钟,此时连接还占用服务器的资源,所以会出现这样情形,性能高的服务器已处理所收到的连接,连接处于TIME_WAIT状态,而性能低的服务器已经 忙于处理所收到的连接,还不断地收到新的连接请求。
2.4. 加权最小连接调度
加权最小连接调度(Weighted Least-Connection Scheduling)算法是最小连接调度的超集,各个服务器用相应的权值表示其处理性能。服务器的缺省权值为1,系统管理员可以动态地设置服务器的权 值。加权最小连接调度在调度新连接时尽可能使服务器的已建立连接数和其权值成比例。加权最小连接调度的算法流程如下:
加权最小连接调度的算法流程
|
2.5. 基于局部性的最少链接调度
基于局部性的最少链接调度(Locality-Based Least Connections Scheduling,以下简称为LBLC)算法是针对请求报文的目标IP地址的负载均衡调度,目前主要用于Cache集群系统,因为在Cache集群中 客户请求报文的目标IP地址是变化的。这里假设任何后端服务器都可以处理任一请求,算法的设计目标是在服务器的负载基本平衡情况下,将相同目标IP地址的 请求调度到同一台服务器,来提高各台服务器的访问局部性和主存Cache命中率,从而整个集群系统的处理能力。
LBLC调度算法先根据请求的目标IP地址找出该目标IP地址最近使用的服务器,若该服务器是可用的且没有超载,将请求发送到该服务器;若服务器不 存在,或者该服务器超载且有服务器处于其一半的工作负载,则用“最少链接”的原则选出一个可用的服务器,将请求发送到该服务器。该算法的详细流程如下:
LBLC调度算法流程
|
此外,对关联变量ServerNode[dest_ip]要进行周期性的垃圾回收(Garbage Collection),将过期的目标IP地址到服务器关联项进行回收。过期的关联项是指哪些当前时间(实现时采用系统时钟节拍数jiffies)减去最 近使用时间超过设定过期时间的关联项,系统缺省的设定过期时间为24小时。
2.6. 带复制的基于局部性最少链接调度
带复制的基于局部性最少链接调度(Locality-Based Least Connections with Replication Scheduling,以下简称为LBLCR)算法也是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。它与LBLC算法的不同之处是它要 维护从一个目标IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP地址到一台服务器的映射。对于一个“热门”站点的服务请求,一台Cache 服务器可能会忙不过来处理这些请求。这时,LBLC调度算法会从所有的Cache服务器中按“最小连接”原则选出一台Cache服务器,映射该“热门”站 点到这台Cache服务器,很快这台Cache服务器也会超载,就会重复上述过程选出新的Cache服务器。这样,可能会导致该“热门”站点的映像会出现 在所有的Cache服务器上,降低了Cache服务器的使用效率。LBLCR调度算法将“热门”站点映射到一组Cache服务器(服务器集合),当该“热 门”站点的请求负载增加时,会增加集合里的Cache服务器,来处理不断增长的负载;当该“热门”站点的请求负载降低时,会减少集合里的Cache服务器 数目。这样,该“热门”站点的映像不太可能出现在所有的Cache服务器上,从而提供Cache集群系统的使用效率。
LBLCR算法先根据请求的目标IP地址找出该目标IP地址对应的服务器组;按“最小连接”原则从该服务器组中选出一台服务器,若服务器没有超载, 将请求发送到该服务器;若服务器超载;则按“最小连接”原则从整个集群中选出一台服务器,将该服务器加入到服务器组中,将请求发送到该服务器。同时,当该 服务器组有一段时间没有被修改,将最忙的服务器从服务器组中删除,以降低复制的程度。LBLCR调度算法的流程如下:
LBLCR调度算法流程
|
此外,对关联变量ServerSet[dest_ip]也要进行周期性的垃圾回收(Garbage Collection),将过期的目标IP地址到服务器关联项进行回收。过期的关联项是指哪些当前时间(实现时采用系统时钟节拍数jiffies)减去最 近使用时间(lastuse)超过设定过期时间的关联项,系统缺省的设定过期时间为24小时。
2.7. 目标地址散列调度
目标地址散列调度(Destination Hashing Scheduling)算法也是针对目标IP地址的负载均衡,但它是一种静态映射算法,通过一个散列(Hash)函数将一个目标IP地址映射到一台服务器。
目标地址散列调度算法先根据请求的目标IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。该算法的流程如下:
目标地址散列调度算法流程
|
在实现时,我们采用素数乘法Hash函数,通过乘以素数使得散列键值尽可能地达到较均匀的分布。所采用的素数乘法Hash函数如下:
素数乘法Hash函数
|
2.8. 源地址散列调度
源地址散列调度(Source Hashing Scheduling)算法正好与目标地址散列调度算法相反,它根据请求的源IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。它采用的散列函数与目标地址散列调度算法 的相同。它的算法流程与目标地址散列调度算法的基本相似,除了将请求的目标IP地址换成请求的源IP地址,所以这里不一一叙述。
在实际应用中,源地址散列调度和目标地址散列调度可以结合使用在防火墙集群中,它们可以保证整个系统的唯一出入口。
3. 动态反馈负载均衡算法
动态反馈负载均衡算法考虑服务器的实时负载和响应情况,不断调整服务器间处理请求的比例,来避免有些服务器超载时依然收到大量请求,从而提 高整个系统的吞吐率。图1显示了该算法的工作环境,在负载调度器上运行Monitor Daemon进程,Monitor Daemon来监视和收集各个服务器的负载信息。Monitor Daemon可根据多个负载信息算出一个综合负载值。Monitor Daemon将各个服务器的综合负载值和当前权值算出一组新的权值,若新权值和当前权值的差值大于设定的阀值,Monitor Daemon将该服务器的权值设置到内核中的IPVS调度中,而在内核中连接调度一般采用加权轮叫调度算法或者加权最小连接调度算法。
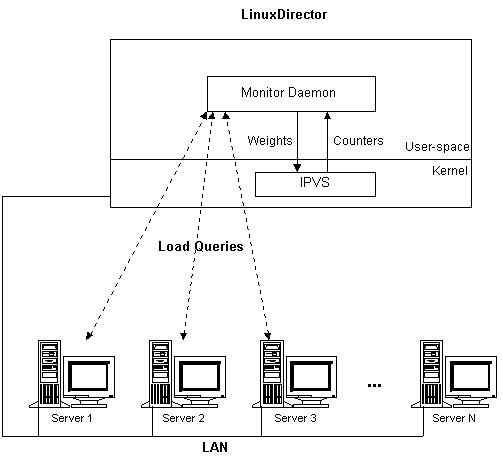
图1:动态反馈负载均衡算法的工作环境
当客户通过TCP连接访问网络访问时,服务所需的时间和所要消耗的计算资源是千差万别的,它依赖于很多因素。例如,它依赖于请求的服务类型、当前网 络带宽的情况、以及当前服务器资源利用的情况。一些负载比较重的请求需要进行计算密集的查询、数据库访问、很长响应数据流;而负载比较轻的请求往往只需要 读一个HTML页面或者进行很简单的计算。
请求处理时间的千差万别可能会导致服务器利用的倾斜(Skew),即服务器间的负载不平衡。例如,有一个WEB页面有A、B、C和D文件,其中D是 大图像文件,浏览器需要建立四个连接来取这些文件。当多个用户通过浏览器同时访问该页面时,最极端的情况是所有D文件的请求被发到同一台服务器。所以说, 有可能存在这样情况,有些服务器已经超负荷运行,而其他服务器基本是闲置着。同时,有些服务器已经忙不过来,有很长的请求队列,还不断地收到新的请求。反 过来说,这会导致客户长时间的等待,觉得系统的服务质量差。
3.1.1. 简单连接调度
简单连接调度可能会使得服务器倾斜的发生。在上面的例子中,若采用轮叫调度算法,且集群中正好有四台服务器,必有一台服务器总是收到D文件的请求。这种调度策略会导致整个系统资源的低利用率,因为有些资源被用尽导致客户的长时间等待,而其他资源空闲着。
3.1.2. 实际TCP/IP流量的特征
文献[1]说明网络流量是呈波浪型发生的,在一段较长时间的小流量后,会有一段大流量的访问,然后是小流量,这样跟波浪一样周期性地发生。文献 [2,3,4,5]揭示在WAN和LAN上网络流量存在自相似的特征,在WEB访问流也存在自相似性。这就需要一个动态反馈机制,利用服务器组的状态来应 对访问流的自相似性。
3.2. 动态反馈负载均衡机制
TCP/IP流量的特征通俗地说是有许多短事务和一些长事务组成,而长事务的工作量在整个工作量占有较高的比例。所以,我们要设计一种负载均衡算法,来避免长事务的请求总被分配到一些机器上,而是尽可能将带有毛刺(Burst)的分布分割成相对较均匀的分布。
我们提出基于动态反馈负载均衡机制,来控制新连接的分配,从而控制各个服务器的负载。例如,在IPVS调度器的内核中使用加权轮叫调度 (Weighted Round-Robin Scheduling)算法来调度新的请求连接;在负载调度器的用户空间中运行Monitor Daemon。Monitor Daemon定时地监视和收集各个服务器的负载信息,根据多个负载信息算出一个综合负载值。Monitor Daemon将各个服务器的综合负载值和当前权值算出一组新的权值。当综合负载值表示服务器比较忙时,新算出的权值会比其当前权值要小,这样新分配到该服 务器的请求数就会少一些。当综合负载值表示服务器处于低利用率时,新算出的权值会比其当前权值要大,来增加新分配到该服务器的请求数。若新权值和当前权值 的差值大于设定的阀值,Monitor Daemon将该服务器的权值设置到内核中的IPVS调度中。过了一定的时间间隔(如2秒钟),Monitor Daemon再查询各个服务器的情况,并相应调整服务器的权值;这样周期性地进行。可以说,这是一个负反馈机制,使得服务器保持较好的利用率。
在加权轮叫调度算法中,当服务器的权值为零,已建立的连接会继续得到该服务器的服务,而新的连接不会分配到该服务器。系统管理员可以将一台服务器的 权值设置为零,使得该服务器安静下来,当已有的连接都结束后,他可以将该服务器切出,对其进行维护。维护工作对系统都是不可少的,比如硬件升级和软件更新 等,零权值使得服务器安静的功能很主要。所以,在动态反馈负载均衡机制中我们要保证该功能,当服务器的权值为零时,我们不对服务器的权值进行调整。
3.3. 综合负载
在计算综合负载时,我们主要使用两大类负载信息:输入指标和服务器指标。输入指标是在调度器上收集到的,而服务器指标是在服务器上的各种负载信息。 我们用综合负载来反映服务器当前的比较确切负载情况,对于不同的应用,会有不同的负载情况,这里我们引入各个负载信息的系数,来表示各个负载信息在综合负 载中轻重。系统管理员根据不同应用的需求,调整各个负载信息的系数。另外,系统管理员设置收集负载信息的时间间隔。
输入指标主要是在单位时间内服务器收到新连接数与平均连接数的比例,它是在调度器上收集到的,所以这个指标是对服务器负载情况的一个估计值。在调度 器上有各个服务器收到连接数的计数器,对于服务器Si,可以得到分别在时间T1和T2时的计数器值Ci1和Ci2,计算出在时间间隔T2-T1内服务器 Si收到新连接数Ni = Ci2 – Ci1。这样,得到一组服务器在时间间隔T2-T1内服务器Si收到新连接数{Ni},服务器Si的输入指标INPUTi为其新连接数与n台服务器收到平 均连接数的比值,其公式为
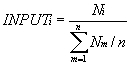
另一个重要的服务器指标是服务器所提供服务的响应时间,它能比较好地反映服务器上请求等待队列的长度和请求的处理时间。调度器上的Monitor Daemon作为客户访问服务器所提供的服务,测得其响应时间。例如,测试从WEB服务器取一个HTML页面的响应延时,Monitor Daemon只要发送一个“GET /”请求到每个服务器,然后记录响应时间。若服务器在设定的时间间隔内没有响应,Monitor Daemon认为服务器是不可达的,将服务器在调度器中的权值设置为零。同样,我们对响应时间进行如上调整,得到RESPONSEi。
这里,我们引入一组可以动态调整的系数Ri来表示各个负载参数的重要程度,其中ΣRi = 1。综合负载可以通过以下公式计算出:
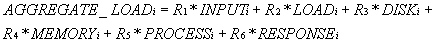
另外,关于查询时间间隔的设置,虽然很短的间隔可以更确切地反映各个服务器的负载,但是很频繁地查询(如1秒钟几次)会给调度器和服务器带来一定的 负载,如频繁执行的Monitor Daemon在调度器会有一定的开销,同样频繁地查询服务器指标会服务器带来一定的开销。所以,这里要有个折衷(Tradeoff),我们一般建议将时间 间隔设置在5到20秒之间。
3.4. 权值计算
当服务器投入集群系统中使用时,系统管理员对服务器都设定一个初始权值DEFAULT_WEIGHTi,在内核的IPVS调度中也先使用这个权值。 然后,随着服务器负载的变化,对权值进行调整。为了避免权值变成一个很大的值,我们对权值的范围作一个限制[DEFAULT_WEIGHTi, SCALE*DEFAULT_WEIGHTi],SCALE是可以调整的,它的缺省值为10。
Monitor Daemon周期性地运行,若DEFAULT_WEIGHTi不为零,则查询该服务器的各负载参数,并计算出综合负载值AGGREGATE_LOADi。我们引入以下权值计算公式,根据服务器的综合负载值调整其权值。

在实际使用中,若发现所有服务器的权值都小于他们的DEFAULT_WEIGHT,则说明整个服务器集群处于超载状态,这时需要加入新的服务器结点 到集群中来处理部分负载;反之,若所有服务器的权值都接近于SCALE*DEFAULT_WEIGHT,则说明当前系统的负载都比较轻。
3.5. 一个实现例子
我们在RedHat集群管理工具Piranha[6]中实现了一个简单的动态反馈负载均衡算法。在综合负载上,它只考虑服务器的CPU负载(Load Average),使用以下公式进行权值调整:

本文主要讲述了IP虚拟服务器在内核中实现的八种连接调度算法:
- 轮叫调度(Round-Robin Scheduling)
- 加权轮叫调度(Weighted Round-Robin Scheduling)
- 最小连接调度(Least-Connection Scheduling)
- 加权最小连接调度(Weighted Least-Connection Scheduling)
- 基于局部性的最少链接(Locality-Based Least Connections Scheduling)
- 带复制的基于局部性最少链接(Locality-Based Least Connections with Replication Scheduling)
- 目标地址散列调度(Destination Hashing Scheduling)
- 源地址散列调度(Source Hashing Scheduling)
因为请求的服务时间差异较大,内核中的连接调度算法容易使得服务器运行出现倾斜。为此,给出了一个动态反馈负载均衡算法,结合内核中的加权连接调度 算法,根据动态反馈回来的负载信息来调整服务器的权值,来调整服务器间处理请求数的比例,从而避免服务器间的负载不平衡。动态反馈负载算法可以较好地避免 服务器的倾斜,提高系统的资源使用效率,从而提高系统的吞吐率。